The ARC Incident
TL;DR: investigating and fixing memory management overhead in the Oryol Metal renderer, OR: why you should never blindly trust automatic memory management solutions
Yesterday evening I revisited the Metal renderer for Oryol. There were some loose ends that needed fixing about some CPU overhead for reference-counting of Objective-C objects in draw-call-heavy stress-test scenes with tens-of-thousands of draw-calls. I got this down from initially 20% to around 7% last October by requesting a command buffer from Metal which leaves the reference counts of its objects alone, but those remaining 7% remained baffling.
A bit of background info: In the default ‘noob-mode’, Metal takes care that resources that have been released on the CPU side are not destroyed until the GPU no longer needs them (just like GL or D3D11). This adds some significant overhead for reference counting (at least it was significant in the first OSX beta with Metal support, might have been optimized in the meantime). In an alternative ‘danger mode’ the programmer needs to care about keeping objects alive that are still in use by the GPU. I simply fixed this by putting all resources that are no longer needed into a ‘deferred release queue’, which keeps all ‘dead’ objects around for 2 more render-frames, and then destroys them, because at that time the GPU is definitely not using them anymore.
Ok, back to those remaining 7% refcounting overhead I was still seeing, even in ‘danger mode’. This was on my MacBookPro, not iPad, and a stress-test with tens-of-thousands of draw calls (the native version of this Oryol DrawCallPerf sample). When I tried the same on my iPad Mini 4, I got some truly shocking results, somewhere between 20% and 40% CPU time spent in _objc_retain and _objc_release!
The DrawCallPerf render loop applies all ‘static state’ required for rendering once per frame, and then in a tight loop, does one Gfx::ApplyUniformBlock() and one Gfx::Draw() per particle, and this for an increasing number of 3D particles until everything blows up. The idea of the demo is to roughly find out how many ‘traditional’ draw calls a 3D API can handle until the framerate goes below 60hz.
The Instruments profiler told me that the problem were _objc_retain and _objc_release calls inside Gfx::ApplyUniformBlock() and not in Gfx::Draw(). In the Metal backend, ApplyUniformBlock() essentially does a memcpy() into a global ‘uniform buffer’, and then binds the current buffer location either to a vertex or fragment shader bind slot.
The code looks like this (without some debug-mode sanity-checks):
id<MTLBuffer> mtlBuffer = this->uniformBuffers[this->curFrameRotateIndex];
uint8* dstPtr = ((uint8*)[mtlBuffer contents]) + this->curUniformBufferOffset;
std::memcpy(dstPtr, ptr, byteSize);
// set constant buffer location for next draw call
if (ShaderStage::VS == bindStage) {
[this->curCommandEncoder
setVertexBuffer:mtlBuffer
offset:this->curUniformBufferOffset
atIndex:bindSlot];
}
else {
[this->curCommandEncoder
setFragmentBuffer:mtlBuffer
offset:this->curUniformBufferOffset
atIndex:bindSlot];
}
Ok ok, the [mtlBuffer contents] call is redundant since it’s returning the same value every time, but at first glance there doesn’t seem to be any evil code which would cause the reference counting go crazy and I lamented as much on twitter.
And then:
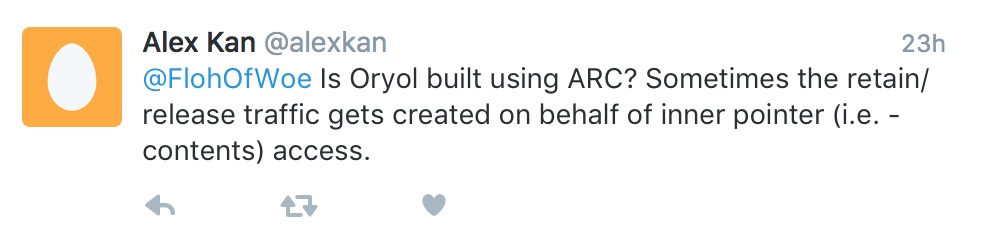
Indeed, Oryol uses ARC (Automatic Reference Counting) when compiled with the Metal backend, and I didn’t pay that much attention to it, since it ‘just worked’, confirmed by the Xcode static code analyzer. But looking at the assembly code for the above function I indeed saw one call each to _objc_retain, _objc_retainAutorelease and _objc_release, and after some experimentation the culprit turned out to be the temporary id<MTLBuffer> variable, not the call to [mtlBuffer contents] as I expected first.
After moving things around a bit (the uniform buffer actually needs to be bound only once per render-pass), this is the new version of Gfx::ApplyUniformBlock() (again, without the debug-mode sanity checks):
uint8* dstPtr = this->curUniformBufferPtr + this->curUniformBufferOffset;
std::memcpy(dstPtr, ptr, byteSize);
if (ShaderStage::VS == bindStage) {
[this->curCommandEncoder
setVertexBufferOffset:this->curUniformBufferOffset
atIndex:bindSlot];
}
else {
[this->curCommandEncoder
setFragmentBufferOffset:this->curUniformBufferOffset
atIndex:bindSlot];
}
this->curUniformBufferOffset = Memory::RoundUp(this->curUniformBufferOffset + byteSize, 256);
Looking at the assembly code, there’s no single reference-counting call to be found anymore, the only remaining subroutine calls are _memcpy and _objc_msgSend:
push {r4, r5, r6, r7, lr}
add r7, sp, #12
str r8, [sp, #-4]!
mov r4, r0
ldr.w r8, [r7, #16]
ldr.w r0, [r4, #232]
mov r5, r1
ldr.w r3, [r4, #236]
mov r6, r2
ldr r1, [r7, #12]
mov r2, r8
add r0, r3
blx _memcpy
ldr.w r0, [r4, #228]
cmp r5, #0
ldr.w r2, [r4, #236]
beq LBB20_2
@ BB#1:
movw r1, :lower16:(L_OBJC_SELECTOR_REFERENCES_63-(LPC20_1+4))
movt r1, :upper16:(L_OBJC_SELECTOR_REFERENCES_63-(LPC20_1+4))
LPC20_1:
add r1, pc
b LBB20_3
LBB20_2:
movw r1, :lower16:(L_OBJC_SELECTOR_REFERENCES_61-(LPC20_0+4))
movt r1, :upper16:(L_OBJC_SELECTOR_REFERENCES_61-(LPC20_0+4))
LPC20_0:
add r1, pc
LBB20_3:
ldr r1, [r1]
mov r3, r6
blx _objc_msgSend
ldr.w r0, [r4, #236]
add r0, r8
adds r0, #255
bic r0, r0, #255
str.w r0, [r4, #236]
ldr r8, [sp], #4
pop {r4, r5, r6, r7, pc}
And indeed, with these simple fixes, all the retain/release overhead has disappeared completely from the profiling session, both on OSX and iOS, yay!